“Recognition and measuring particles on microscopy images is an important part of many scientific studies, including catalytic investigations. In this paper, we present the results of the application of deep learning to the automated recognition of nanoparticles deposited on porous supports (heterogeneous catalysts) on images obtained by transmission electron microscopy (TEM). The Cascade Mask-RCNN neural network was used. During the training, two types of objects were labeled on raw TEM images of ‘real’ catalysts: visible particles and overlapping particle projections. The trained neural network recognized nanoparticles in the test dataset with 0.71 precision and 0.72 recall for both classes of objects and 0.84 precision and 0.79 recall for visible particles. The developed model is integrated into the open-access web service ‘ParticlesNN’, which can be used by any researcher in the world. Instead of hours, TEM data processing per one image analysis is reduced to a maximum of a couple of minutes and the divergence of mean particle size determination is approximately 2% compared to manual analysis. The proposed tool encourages accelerating catalytic research and improving the objectivity and accuracy of analysis.”
Advanced microscopy techniques, such as transmission electron microscopy (TEM), are widely used in modern materials science, and in particularly in catalysis. In heterogeneous catalysis, the catalyst usually consists of an active component deposited as nanoparticles on a support [
1,
2,
3,
4,
5,
6]. The active component and porous supports can be of different nature but are commonly well suited to electron microscopy experiments [
1,
3,
5]. TEM study is widely used during the preparation of catalysts, developing approaches to morphology, composition control, and ways to support particle stabilization [
1,
3,
5,
6], investigation of size effects in catalytic activity [
4], ‘particle–support’ interaction [
1,
3], or catalyst activation/deactivation and sintering [
1,
2]. To compare catalysts, it is necessary to know the particle’s parameters, including size, amount, coverage of the surface, etc. The main information that can be obtained on the basis of TEM image analysis is the size of particles, mean particle size, and particle size distribution [
1,
2,
7]. When microscopy is used for these purposes, processing data on hundreds of particles from several points of the catalyst is required, the more the better [
1,
2], so common manual analysis can take hours. Therefore, having an accessible and simple to use tool for automatic object recognition, size measurement, and statistical analysis can significantly decrease the work of researchers and the time for experiments.
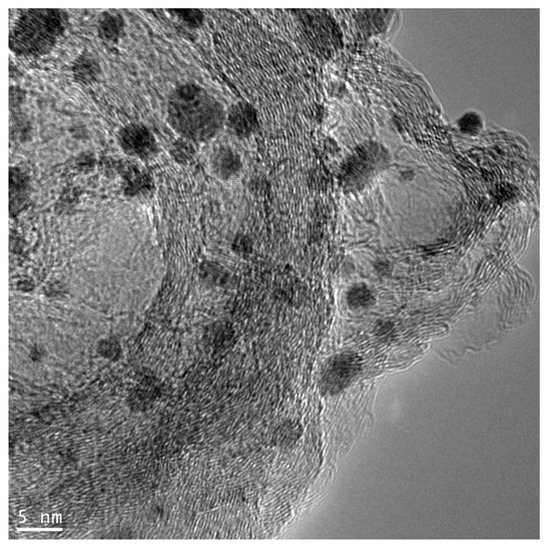
TEM data of ‘real’ catalysts is complicated for image analysis. In , a typical TEM image of the supported catalyst is shown. The non-uniform background, overlapping of the particle projections, and ‘thickening’ of the support material are visible in the image, causing problems in particle identification for users, and making it impossible to use approaches based on conventional image processing methods (automatic selection mode for the image parts with heights above the threshold or determination of boundaries by matrix filtering [
8]). New approaches to conduct these tasks need to be found. For these purposes, the use of deep neural networks, or artificial intelligence, looks very promising.
Figure 1. Typical TEM image of the support catalyst (Pt nanoparticles on carbon support ‘Sibunit’).
A new approach to image analysis, based on deep convolutional neural networks [
9], appeared in 2012. An important aspect of this method is that it takes into account the context of where objects are located. Images with marked objects are used to train the recognition software in automatic mode. In recent years, promising opportunities for this approach were put into practice and the progress in this field of knowledge is notable. Today, deep neural network software products can determine the object type and perform semantic image segmentation, that is, identifying pixels belonging to this object [
10,
11]. Counting the objects and determining their statistical parameters is a common task in basic research. Recently, deep machine learning methods have been successfully used for different purposes. Progress is observed in biology [
12,
13,
14,
15], materials science [
7,
16], and thermophysics [
17]. There are two common approaches to user interface for research imaging data processing. The first is a classic one, when a user has to install the software and learn how to work on it, e.g., CellProfiler [
18], ilastik [
19], and ImageJ/Fiji [
20]. The second one that appeared recently involves working through an online service, when a user uploads images and receives recognized objects and their parameters, e.g., Cellpose [
12] and DeepCell Kiosk [
21].
As mentioned above, in recent years, the number of publications devoted to the use of deep learning for automatic object recognition in materials science and related fields is increasing gradually [
7,
19,
22,
23,
24,
25,
26,
27,
28,
29,
30]. Of course, due to the practical importance of different types of electron microscopy, developing automatic image processing is very desirable [
27,
28,
29,
30]. Limited results have been achieved in this field using semiautomatic tools and applying neural networks. Semiautomatic tools commonly include the preprocessing of raw ‘noisy’ microscopy data [
8], such as background averaging and subtracting, level-based segmentation, and edge detection [
8,
31,
32,
33]. The primary issue related to this approach is the mandatory selection of empirical parameters that leads to a loss of universality.
In 2019, simultaneously with our first work [
22], our colleagues applied the MO-CNN neural network [
34] and the Mask-RCNN [
35] to find the localization of nanoparticles on TEM images. The size of TEM projections of spherical particles was finally determined by fitting them with circles. An approach based on manually labeling particle positions on experimental TEM images of inorganic nanoparticles spatial dispersion in an organic polymer matrix diverse polymer composite system was used in this work [
29]. An automated pipeline is established that takes a large TEM image as input and extracts inorganic nanoparticle’s locations and sizes. The dataset, Python source code, and trained model are shared on GitHub [
29]. The proposed approach is accessible for users that have coding skills. The dataset used is still not multi-purpose since the organic polymer matrix provides a uniform background for perfectly spherical, sharply contrasting inorganic nanoparticles. In 2021, a similar approach was described for the size characterization of titanium dioxide particles present in the form of agglomerates in images obtained by scanning electron microscopy. This applied an algorithm from the deep statistical learning community, the Mask-RCNN, coupled with transfer learning to overcome the generalization problem in commonly used image processing methods, such as watershed or active contour [
30]. It should be noted that electron microscopy images used for analysis in the referenced papers are characterized by uniform and homogenous noise; the particles are clearly visible and have a rounded shape. These images are close to ideal and quite simple for analysis.
In general, the task of recognizing nanoparticles on TEM images of ‘real’ catalysts on porous supports (see ) is more complicated and involves specific issues. A general approach to resolving the task of recognizing nanoparticles on raw complicated microscopy images was developed by our group using scanning tunneling microscopy (STM) images [
7,
22]. One of the most important results of this work was the creation of the ParticlesNN web service for the automatic search and recognition of nanoparticles on images of scanning probe microscopies (SPM) using a neural network trained by us. The web service is available to any researcher anywhere in the world, no coding skills are required, analysis time is minimized to a maximum of a couple of minutes instead of hours, and the accuracy of mean particle size determination is approximately 5% for STM data compared to manual analysis [
7]. At the same time, parameters of the neural network training on probe microscopy images are applicable only for SPM images or for scanning electron microscopy images of the similar view. The SPM option of the ParticlesNN web service is not suited for transmission electron microscopy, the most widely used microscopy technique in modern catalysis.
The current work presents a service for automatic image data processing based on the use of deep neural networks for TEM image analysis. This service is integrated into the ParticlesNN web service with a pre-trained neural network for the online recognition of nanoparticles in transmission electron microscopy images. The recognition results allow statistical analysis of the data obtained (size, quantity and area of particles, and size distribution histograms). It is important that, compared to the ‘STM version’, the proposed model takes into account both visible particles of any shape and particle overlapping/support artifacts identified as dubious objects. Users have the option to make the final decision about statistical analysis of such objects. A disadvantage of the proposed approach is the dependence of the result of recognition on the dataset used for neural network training. When a new image processed with the ParticlesNN is not similar to dataset images, we could expect a decrease of the accuracy of the recognition. At the same time, this feature is an advantage of the deep neural network approach since the dataset can be extended and the neural network can be re-trained, retaining the quality of the recognition of the images. Another peculiarity is the dependence of the service on the graphics server at the Novosibirsk State University Higher College of Informatics. ‘Off line work’ is not available. Meanwhile, this approach allows any user not to worry about additional high-priced equipment or the need to download additional software. Other advantages of the ParticlesNN web service include: the service is free, with no trial period; the service is user friendly, as no coding skills are needed; the results of recognition are available as tables and images.
2. Results and Discussion
2.1. Training
The goal of this work was to obtain an indubitable automatic statistical analysis of TEM data able to serve as a research tool for experimental work assistance. The primary required information is the size of the particles to establish a particle size distribution and calculate the mean particle size. In order to make this training dataset, particles were thoroughly labeled by an expert along the visual borders of the particles forming ground truth contours.
As mentioned above, the main problem with TEM image analysis is the particle projection overlapping or thickening of the support leading to intensive absorption, making patterns that are similar to the particles but usually with an arbitrary shape. To resolve this problem, two types of ground truth contours for objects with different legends were used for training (see ):
Figure 2. TEM images of Pt on alumina catalyst with ground truth contours: (a) individual ‘Face’ particles; (b) overlapping but visible ‘Face’ particles; (c) overlapping ‘Bottom’ particles with poorly visible borders.
Class 1 ‘Face’ particles, visible ‘by eye’ contours, where particle size can be measured precisely;
Class 0 ‘Bottom’ particles, overlapping (overlapping with other particles or with thickening of the support) when particle contours are poorly visible (size measurement is impeded).
The dataset described in was used for training. After training, the mAP value was 25.3%, which is slightly lower than what was achieved for previous STM data, namely 27.9% [
7]. This can be explained by the uniformity of objects in STM images compared to the diversity of features in TEM images, as well as the small number of ‘Bottom’ particles.
Table 1. Training dataset.
An analysis of the quality of neural network predictions is described in the work [
7]. Predicted contours were distributed in three general categories:
(a) True positive (TP) predictions: predicted and ground truth (GT) contours to a large extent coincide or at least mark the same particle;
(b) False positive (FP) predictions: predicted contours to a large extent missed any GT contours;
(c) False negative (FN) predictions: GT contour has no close correspondence to predicted contours.
If for GT contour more than one predicted contour was found, just one of them was described as TP, while others were referred to as FP.
Using such classifications, one can calculate precision and recall (accuracy) for each recognized image and the test dataset as a whole:
The recognition of predicted contours as TP, FP, or FN was made by the same algorithm as was used in the work [
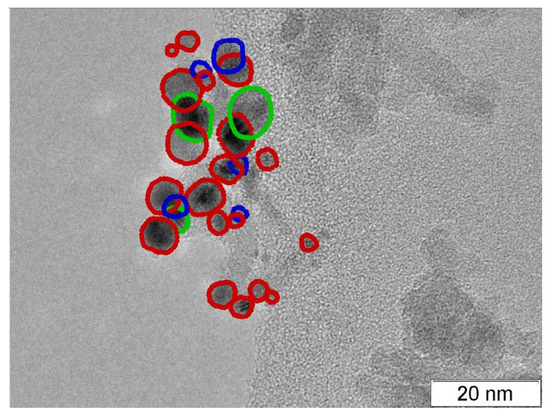
7]. presents an example of TEM image recognition from the test dataset: any predicted contour with a center inside of the GT contour was considered a TP prediction; other predicted contours were FP; GT contours passed by any predicted contours were set as FN. If a predicted contour included more than one GT contour, only one ground truth contour was set as a TP and all other included contours as FN (). summarizes the inference results for all five test images of the test dataset.
Figure 3. TEM image of Pt on alumina catalyst from test dataset with 19 ‘Face’ TP (red), 3 ‘Bottom’ TP (green), 5 ‘Bottom’ FN (blue).
Table 2. Result of predicted contour analysis.
Table 3. Summary of the quality of the particle count in the test dataset.
As expected, the precision and recall for ‘Bottom’ particles is rather low since it is common for the number of such contours to be low. Nevertheless, such contours are ambiguous and candidates for elimination from the statistical analysis. The appearance of such contours in predictions is cause for a targeted analysis by the user.
The developed TEM image analysis model was integrated into the ParticlesNN web service (
http://particlesnn.nsu.ru, accessed on 12 January 2022) as the Processing ML model “TEM image processing v. 1.1”. The analysis described below was performed using ParticlesNN.
For the used dataset, the typical TEM images of metal nanoparticles on porous supports were chosen, restricting the application of the TEM model of the ParticlesNN web service with similar images, namely those well seen by eye particles of the near-circular or elongate shape over non-uniform background of support. Meanwhile, the proposed approach allows dataset extension and neural network re-training, increasing the quality of recognition. We are continuously working on labeled dataset development as new TEM images of the catalysts we are working with are accumulating.
2.2. Comparison with Manual Analysis
For the recognized contours, the area of each particle within the contour and projected area diameter (d = (4S/π)0.5) are calculated automatically by ParticlesNN.
A typical TEM image of the catalyst Pt-Pd/Al
2O
3 was taken to compare the results of particle size analysis made by ParticlesNN and manually using common ImageJ software [
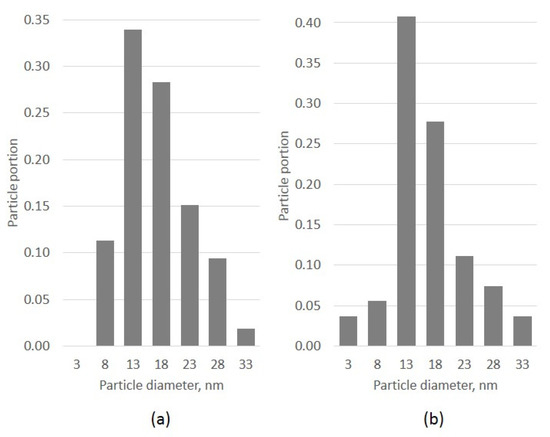
20]. The results of the analysis are shown in and and . It is clear that the mean particle sizes estimated by both methods match each other, with a divergence of ~2%. This is good enough for research. Particle size histograms for both approaches are the same shape. It should be mentioned that ParticlesNN processing time per image is less than 1 min and manual analysis can take hours depending on the user’s experience.
Figure 4. Result of particle recognition of TEM image of Pt-Pd on alumina catalyst processed by ParticlesNN (a) (‘Face’ particles are of green coloration; ‘Bottom’ are of blue coloration; pink coloration for ‘edge particle’): crops of processed image (b) and original image (c).
Figure 5. Particle size histograms: ParticlesNN (a) and manual analysis (b).
Table 4. Processing of TEM image: comparison of ParticlesNN and manual analysis.
Using manual identification, the operator found 54 particles. Processing by ParticlesNN identified 53 ‘Face’ particles and 7 ‘Bottom’ particles. Two particles were identified as ‘edge particles’, which is optional. In b,c, a false positive particle, located at the place of support material thickening, is visible and a set of particles clearly visible by the naked eye was missed by ParticlesNN (a). Nevertheless, the set of truth positive particles is representative enough to get an accurate match of mean sizes obtained by ParticlesNN and ImageJ. Missed recognitions due to support material thickening, is a typical data analysis operator error. This can be eliminated, for example, by additional experiments with higher resolution but this is not always possible.
Moreover, in b,c, the overlapping of ‘Face’ and ‘Bottom’ particles (blue coloration) is visible. Researchers would recognize this particle as ambiguous for particle size measurement. Labeling the particles with the ‘Bottom’ legend, made by ParticlesNN, is useful to exclude such questionable particles from the statistical analysis. From this point of view, misrecognition of the ‘Bottom’ particle type is preferable since the user can exclude or adjust mistrusted particles during the post-processing stage.
When supported particles are spherical or quasi-spherical shaped, manual size measuring is relatively routine. However, particles can be elongated or present with an arbitrary shape, causing a lot of complications and increasing the analysis time. and show the results of particle size measurement of elongated particles by ParticlesNN and manually. To get the mean particle diameter manually, we need to measure the two main diameters and calculate the mean diameter (b) or measure the ‘diagonal’ diameter, which can only be done by experienced researchers. ParticlesNN calculates the diameter precisely based on the number of each particle’s pixels and gives a projected particle diameter (d = (4S/π)0.5) that can be used for direct statistical analysis. The determined diameter agrees precisely with the results of thorough manual measurement (see ). So, the divergence of the ParticlesNN and manual ImageJ size measurements for individual truth positive contours is less than 1%. The difference of mean particle size between ParticleNN and ImageJ obtained for the whole image originates from false positive and false negative contours. The contribution of FN and FP particles is smoothed by the large number of analyzed particles and the total error stays within 2%.
Figure 6. Result of particle recognition of TEM image processed by ParticlesNN (a) and manual size measuring by ImageJ (b).
Table 5. Particle size measuring by ParticlesNN and manually.
A comparison of STM and TEM models of particle recognition shows that the accuracy of a particle search is better for STM images (Precision is 0.93, Recall is 0.78 [
7]), but particle size determination accuracy is higher for TEM data (2% versus 5%). Particles on TEM images have sharper borders due to a contrast in comparison to STM. At the same time, the variability of artifacts on TEM images causes issues with a TP contour search.
It is important to know that the result of image processing by the ParticlesNN web service is presented not just as a BMP file, where predicted contours are plotted on the original image, but also as a JSON file. Using the LabelMe program the operator can exclude FP, add FN, or adjust TP contours and upload the adjusted file in ParticlesNN for corrected statistics, which decreases the analysis error.
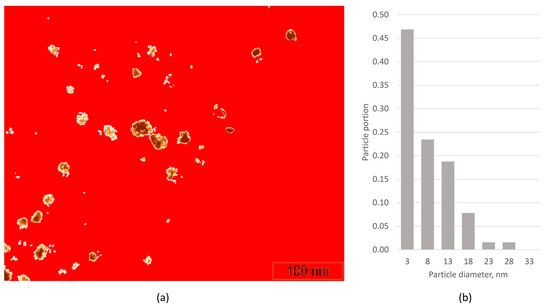
We also compared our service with available software for automatic object detection. a shows the result of the application of the “flooding” procedure in the WSxM software [
36] for the TEM image in a. Particles look like dark spots, so ‘holes’ were chosen for recognition by threshold adjustment. Flooding found 64 objects, the mean projected diameter was 9 nm. b shows a histogram of the particle size distribution, which differs significantly from those of . It can be easily observed with manual analysis that the increase in particle number and decrease in mean particle size are the result of: (1) false recognition of the dark spots of the support material thickness non-uniformity; (2) distortion of the particle shape/contour due to the particle’s coloring non-uniformity. We obtained similar results by threshold analysis using Digimizer software [
37]. For better results, both threshold and min/max length adjustments were used. Mean particle length was 9.0 nm with standard error of 16.7 nm, which is far from manual analysis. So, we conclude that the procedures based on threshold approaches work poorly for TEM images of samples of catalysts on porous supports. Moreover, such procedures do not consider particle projection overlapping.
Figure 7. Processing of the TEM image (a) by the “flooding” procedure in WSxM software (a); particle size distributions of the defined 64 contours (b).